Top CryoET U-Net Picker (TopCUP)
Version v1.0.1 released 21 Oct 2025
License
MIT LicenseThe Top CryoET U-Net Picker (TopCUP) is a 3D U-Net type ensemble model for particle picking in cryoET volumes that is based on a segmentation heatmap approach. The model is part of the 1st place solution of the CryoET Object Identification Kaggle competition organized by the Chan Zuckerberg Imaging Institute (CZII). TopCUP was trained on the Phantom dataset available through the CryoET Data Portal and is integrated with copick, a cryoET dataset API used for accessing data across platforms.
Developed By
Model Details
Model Architecture
TopCUP is an ensemble of multiple segmentation models from MONAI. The model is primarily based on the FlexibleUNet class from MONAI with a 3D-EfficentNet-B3 encoder. To improve efficiency its decoder is reduced to three layers.
Parameters
70.7 million
Citation
Peck, A., et al., (2025) A Realistic Phantom Dataset for Benchmarking Cryo-ET Data Annotation. Nature Methods. DOI: 10.1101/2024.11.04.621686.
Model Card Authors
Kevin Zhao (CZII) and Christof Henkel (NVIDIA)
Primary Contact Email
Christof Henkel chenkel@nvidia.com, Kevin Zhao kevin.zhao@czii.org
To submit feature requests or report issues with the model, please open an issue on the GitHub repository.
System Requirements
The model was successfully tested on the following NVIDIA GPUs: V100, A100, H100, H200, T4
Model Variants
Model Variant Name | Description | Access URL |
|---|---|---|
| Kaggle CryoET 1st Place Segmentation Model | Part of the original models submitted to win the CryoET Kaggle challenge. This version is not integrated with copick and cannot be easily used with datasets outside of those used for the challenge. | https://github.com/ChristofHenkel/kaggle-cryoet-1st-place-segmentation/tree/main |
Intended Use
Primary Use Cases
- Particle picking in cryoET volumes
Out-of-Scope or Unauthorized Use Cases
Do not use the model for the following purposes:
- Use that violates applicable laws, regulations (including trade compliance laws), or third party rights such as privacy or intellectual property rights.
- Any use that is prohibited by the MIT License.
- Any use that is prohibited by the Acceptable Use Policy.
Training Details
Training Data
The original training dataset consisted of seven experimental tomograms with ground truth annotations for six protein complexes.This dataset is publicly available on the CryoET Data Portal under Dataset ID: DS-10440. To train additional models and improve generalization, we also included annotated tomograms from the Public Testing Dataset (ID: DS-10445).
Training Procedure
Users need to create a copick configuration file that contains particle descriptions and follow the CLI instructions to train the model. Training TopCUP models can benefit significantly from data augmentation, especially when working with smaller training datasets. Users can experiment with different augmentation repetitions using the command option -n or --n_aug.
Training Code
https://github.com/czimaginginstitute/czii_cryoet_mlchallenge_winning_modelsSpeeds, Sizes, Times
About 30 minutes per epoch on A100/H100 GPU using the Training Dataset (Dataset ID: DS-10440).
Training Hyperparameters
Training hyperparameters are user-defined and may vary for different particles or datasets. Three parameters should be specified within the metadata field present in the copick configuration file (see Quickstart: TopCUP). These parameters are defined below:
class_loss_weight: weight for each class in the DenseCrossEntropy lossscore_threshold: threshold to filter final picks per class, reducing false positivesscore_weight: weight for each class in the F-beta score evaluation
Data Sources
CZII - CryoET Object Identification Challenge Datasets:
- Experimental Training Dataset (ID: DS-10440)
- Public Testing Dataset (ID: DS-10445)
Performance Metrics
Metrics
F-beta score with a beta value of 4 (the same metric used in the Kaggle challenge)
Evaluation Datasets
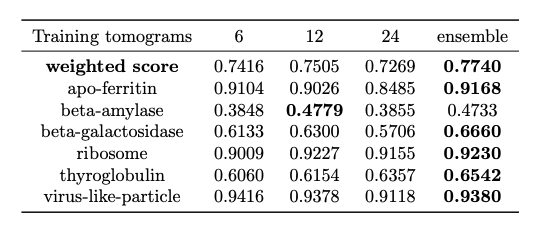
TopCUP is an ensemble of models trained on tomograms prior to inference. For performance evaluation, three models were trained separately with either 6, 12, or 24 experimental tomograms from scratch, which were selected from the Training dataset (ID: DS-10440) and the Public Testing dataset (ID: DS-10445). The final evaluation was conducted on the entire Private Testing (ID: DS-10446) dataset, which was used by the final Kaggle Leaderboard to score models. These models achieved an ensemble score of 0.774 (see evaluation results below).
Evaluation Results
Biases, Risks, and Limitations
Potential Biases
- Model performance is subjected to the types of particles and their distribution within the training dataset.
Risks
- Inaccurate predictions (False Positives and False Negatives)
Limitations
- The model may need retraining for new datasets.
Caveats and Recommendations
- Review and validate outputs generated by the model.
- We are committed to advancing the responsible development and use of artificial intelligence. Please follow our Acceptable Use Policy when using the model.
- Should you have any security or privacy issues or questions related to this model, please reach out to our team at security@chanzuckerberg.com or privacy@chanzuckerberg.com respectively.
Acknowledgements
We thank Eugene Khvedchenia from NVIDIA for developing the object detection model (the other half in the original submission of the 1st place solution), which will be added to TopCUP in the future. We thank the support and computing resources from CZI, Biohub Network, and the CZ Imaging Institute.
If you have recommendations for this model card please contact virtualcellmodels@chanzuckerberg.com.